
细说docker - 容器技术
docker对于现在的我们来说,已经是一个非常熟悉的东西了,docker无论是在部署打包,自动化,等方方面面都起着重要的作用,但是你是否有疑问,docker究竟是如何帮我们创建一个个隔离的环境的呢?今天我们就来看看,仔细说说docker
PS: 以下的讨论都限定在linux环境下,在windows和macos下容器技术实现不相同,不在讨论范围内。
大方向
为什么先要提到这个词呢?因为所有在操作系统上运行的程序都叫做进程。docker也不例外,从大的方向来讲,docker就是帮你创建了一个进程而已。而不一样的是,docker通过限制了各种环境,就像给这个进程画了一个圈,所以在这个进程本身看来,它自己好像被隔离了一般。
- docker容器技术的核心,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”
限制条件
那么我们有了大方向,那么来细细看看,首先的第一个问题就来了,docker是通过什么方法对这个进程进行限制的呢?
Namespace
命名空间,没错就是它,是它限制了docker容器的环境。其实这是linux的一个功能而已,只不过没人想到docker会那它来做这个事情。下面看个例子,一下是我在一个nginx容器中利用ps命令查看的进程样子
1 | / # ps -ef |
我们可以看到,PID是从1开始的,当前宿主机肯定也有PID为1的进程,这说明容器中所有的进程看起来好像和宿主机隔离了。其实这就是利用了 CLONE_NEWPID
我们知道,在linux下可以利用clone(main_function, stack_size, SIGCHLD, NULL);
方法创建进程,如果同时你再参数中设定参数CLONE_NEWPIDclone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
那么新创建的进程就会在一个新的空间下,在这个空间中它自己的pid就是1;而其实在主机本身看来这个进程的pid还是一个别的数字。
由于新的进程在它自己的空间中认为自己是1号进程,所以看起来好像就和主机本身进程隔离的一样, 而其实只是它看不到别人罢了。这就是Namespace的作用。
同样的 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通过这些选项我们就能创建出一些隔离于宿主机的网络,挂载点等等,从而实现了环境上的限制。
CGroups
当我们利用Namespace搞了一个相对隔离的环境,但是有些东西Namespace没有办法搞,比如CPU和内存。
我们知道如果使用vm等一些虚拟化软件进行虚拟机的创建你是可以给虚拟机设定cpu使用的核心数还有内存的使用量,来保证虚拟机不会超过使用的量而导致别的虚拟机无法使用。
而在docker容器中好像我们看似没有什么限制条件来约束一个容器的cpu和内存,如果没有约束那么很容易出现的问题就是,一个容器的运行吃掉了全部的cpu资源或者是一个容易的内存泄漏导致吃掉了整个服务器的内存资源,这是我们不希望看到的。
于是CGroups技术就是干这个事情的。CGroups其实叫做Linux Control Group,就是用来限制一个进程的使用个资源上限的,包括 CPU、内存、磁盘、网络带宽等等。
我们可以进入/sys/fs/cgroup这个目录下就能看到CGroups所有的限制都在里面了。
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
这里对于CGroups就不细说了,只要知道它能帮助我们限制这些就足够了。
chroot
在namespace和cgroup的隔离之后,docker还有一个步骤需要做的是,如何去隔离文件系统。
因为即使开启了Mount Namespace 但是容器进程也能看到宿主机的文件系统,因为Mount Namespace修改的是容器进程对文件系统挂载点的认知,但是如果没有执行mount命令,那么当前还是使用的宿主机的文件系统,但这肯定不是我们想要的。
而在linux下有一个命令很好的解决了这个问题,那就是chroot。这个命令是 change root directory 的缩写,意思就是切换当前系统的root目录。我们知道在linux系统中根路径就是“/”,使用这个命令就可以切换我们的根路径变成别的路径。
docker就是使用chroot来实现说让docker容器所有在的目录的根目录进行修改,从而在容器角度看来是看不到宿主机的目录,因为它会认为自己这里就是根目录了。
对于chroot详细的介绍这里就不展开了,感兴趣可以查看:https://www.ibm.com/developerworks/cn/linux/l-cn-chroot/index.html
镜像
从上面我们已经可以知道,docker通过 namespace、cgroup、chroot 技术帮我们创建了一个拥有限制条件和隔离环境的进程,从而实现了一个容器,但是还有一个重要的技术在docker中也是至关重要的,那就是镜像。
在使用docker的时候,最方便的莫过于你可以通过docker build命令进行镜像的制作,然后将镜像推送到远端的仓库中去,任何机器只需要连接仓库拉取镜像就可以构建出一模一样的容器,那么镜像里面究竟放了什么东西呢?
镜像的本质
其实 docker 镜像本身就是一个压缩包,它将我们制作好的文件系统打包好了。
我们可以用 docker export 对镜像文件进行导出。我们会发现其实镜像中的目录结构和linux一样,其实就是一个文件系统。
镜像分层技术
但是如果仅仅是做一个简单的文件打包的工作,那么你就太小看docker镜像本身了。
那说到实现,首先要说说 UnionFS(Union File System)它的功能非常简单,就是将多个不同位置的目录联合挂载到同一个目录下,并且如果目录下具有相同的文件会被合并。就是这个功能让docker实现了镜像这个东西。
当前我们在制作镜像的时候,在 docker-file 中每一条 docker 指令都会构建一个 lay,每个 lay 其实都是对已有的文件系统做一个操作,最终docker会把所有的 lay 通过 UnionFS 挂载到同一个目录下面,从而就实现了镜像分层后最终还是一个完整的文件系统的操作。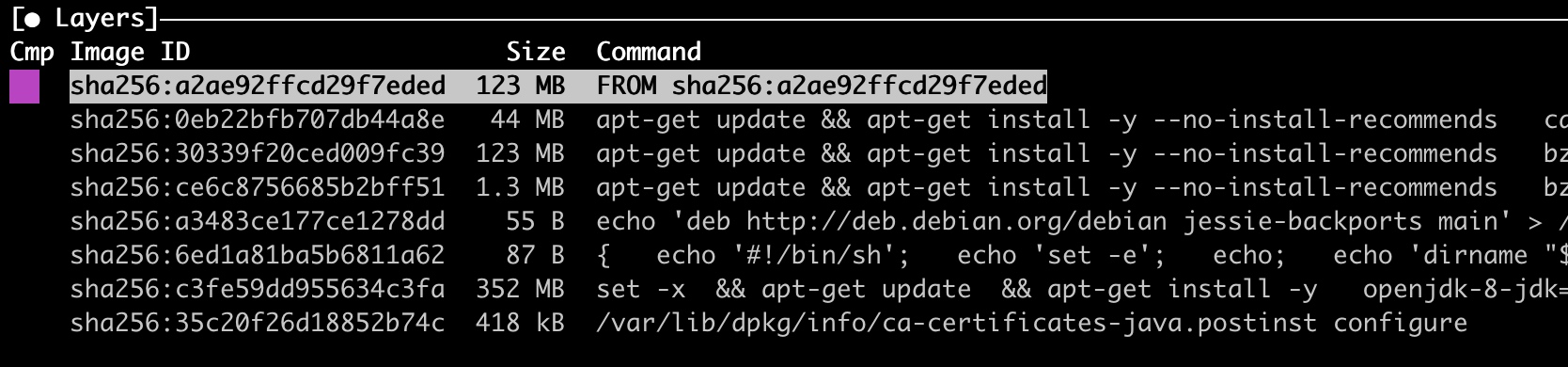
需要注意的是,当前我们在使用镜像的时候,我们在 run 一个 docker 之后里面的一些应用往往会对新创建的文件系统做出修改,如:创建日志文件。但是当我们删除这个容器的时候会发现,其实这个些创建的文件是不会被写入到镜像中去的。
这是因为,docker中的层是不一样的,有只读层,可读写层,init层。当镜像被 docker run 命令创建时就会在镜像的最上层添加一个可读写层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。容器和镜像的区别就在于,所有的镜像都是只读层的,而每一个容器其实等于镜像加上一个可读写的层。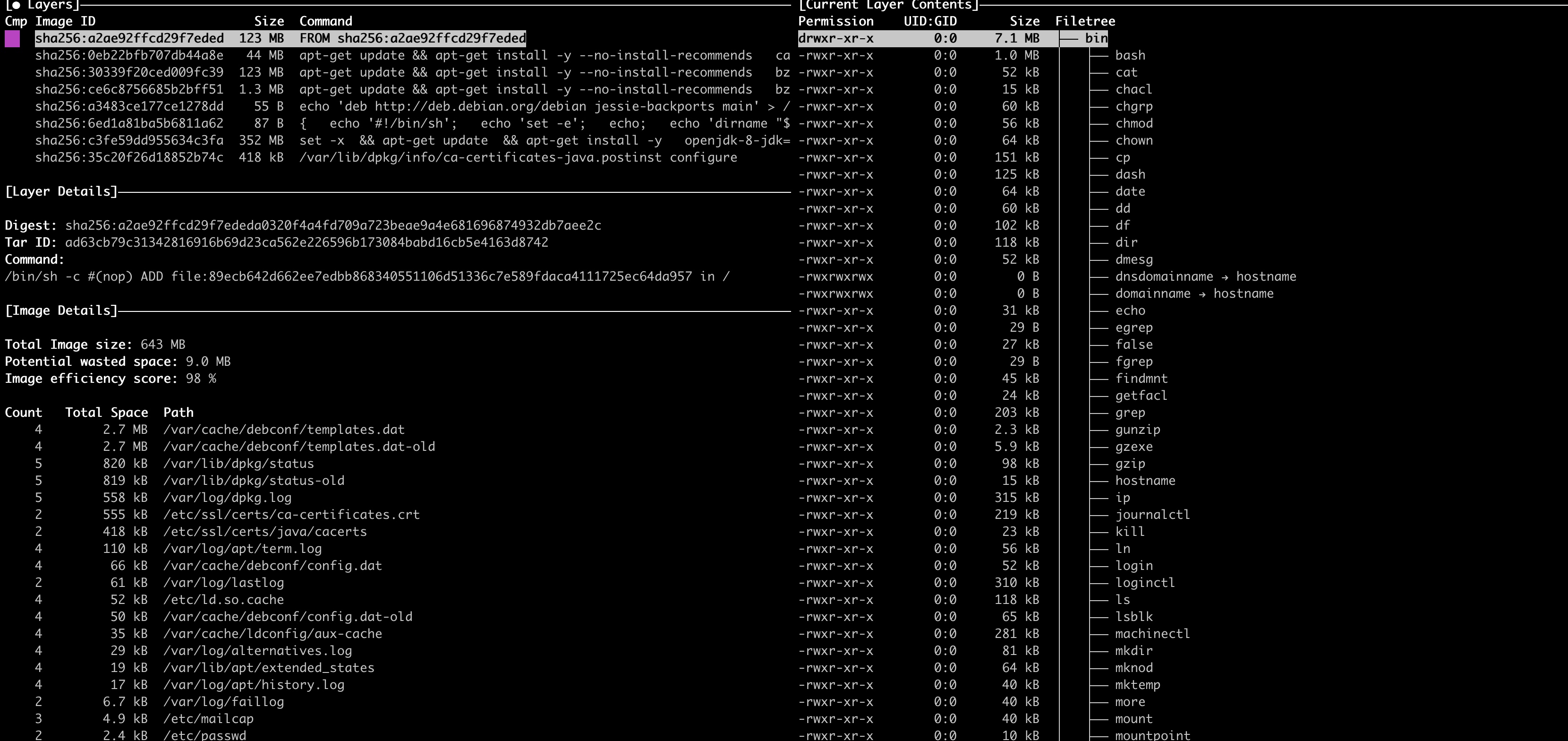
这是我通过 dive 工具查看java这个docker镜像所示的东西,可以清楚的看到它的分层情况,是通过一层层叠加而来,而右边就是它的文件系统里面的样子了。
总结
Docker 使用namespace、cgroups、chroot画了一个圈,圈出了一个近乎独立的环境,而其本质还是一个进程。使用UnionFS来实现了镜像分层的整合,从而让docker镜像实现了分层构建。
总的来说,其实docker看起来非常厉害,启动一个容器飞快比传统的虚拟机好用了太多,在不知道实现原理的情况下,感觉很神奇。但是了解之后你会发现,其实docker运用的技术并不复杂,它只是将一些已有的技术做了一个整合,这些技术也并非docker去创造的,namespace、cgroups都是linux提供的功能罢了。但是在docker出现以前,谁能想到这些东西组合在一起就能碰撞出不一样的火花呢?
 微信
微信 支付宝
支付宝

