intaeProcessEvents(aeEventLoop *eventLoop, int flags) { int processed = 0, numevents;
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return0;
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { int j; structtimeval tv, *tvp = NULL; /* NULL means infinite wait. */ int64_t usUntilTimer;
if (eventLoop->beforesleep != NULL && (flags & AE_CALL_BEFORE_SLEEP)) eventLoop->beforesleep(eventLoop);
if ((flags & AE_DONT_WAIT) || (eventLoop->flags & AE_DONT_WAIT)) { tv.tv_sec = tv.tv_usec = 0; tvp = &tv; } elseif (flags & AE_TIME_EVENTS) { usUntilTimer = usUntilEarliestTimer(eventLoop); if (usUntilTimer >= 0) { tv.tv_sec = usUntilTimer / 1000000; tv.tv_usec = usUntilTimer % 1000000; tvp = &tv; } } /* Call the multiplexing API, will return only on timeout or when * some event fires. 注意这里!!!!!!!!!!!!!! */ numevents = aeApiPoll(eventLoop, tvp);
/* Don't process file events if not requested. */ if (!(flags & AE_FILE_EVENTS)) { numevents = 0; }
/* After sleep callback. */ if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP) eventLoop->aftersleep(eventLoop);
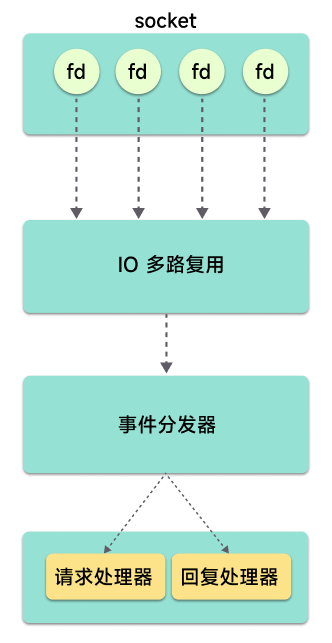
for (j = 0; j < numevents; j++) { int fd = eventLoop->fired[j].fd; aeFileEvent *fe = &eventLoop->events[fd]; int mask = eventLoop->fired[j].mask; int fired = 0; /* Number of events fired for current fd. */
int invert = fe->mask & AE_BARRIER;
if (!invert && fe->mask & mask & AE_READABLE) { /* rfileProc 在处理什么事件呢? */ fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; fe = &eventLoop->events[fd]; /* Refresh in case of resize. */ }
/* Fire the writable event. */ if (fe->mask & mask & AE_WRITABLE) { /* wfileProc 在处理什么事件呢? */ if (!fired || fe->wfileProc != fe->rfileProc) { fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } }
/* If we have to invert the call, fire the readable event now * after the writable one. */ if (invert) { fe = &eventLoop->events[fd]; /* Refresh in case of resize. */ if ((fe->mask & mask & AE_READABLE) && (!fired || fe->wfileProc != fe->rfileProc)) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } }
processed++; } } /* Check time events */ if (flags & AE_TIME_EVENTS) processed += processTimeEvents(eventLoop);
return processed; /* return the number of processed file/time events */ }

 微信
微信 支付宝
支付宝