
图解goroutine调度
其实这个话题我早就想做了,奈何这个问题确实有点复杂,看了很多文章才有了一点点自己的理解。从golang一开始的使用我就已经开始好奇了,这个goroutine到底是怎么实现的呢?怎么就能搞出一个和线程类似,但是性能又那么好的东西的呢?
模型
三个小伙子
在看整体结构之前,我先来介绍三个小伙子,golang为了实现goroutine,定义了这样三个小伙子,让他们帮忙去实现。
G
表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
M
M代表着真正的执行计算资源。在绑定有效的P后,进入调度器循环;而调度器循环的机制大致是从各种队列、P的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M,如此反复。M并不保留G状态,这是G可以跨M调度的基础。
P
表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
整体结构模型
我们先来看下面的这张图,从大体结构上看,我们就能理解goroutine了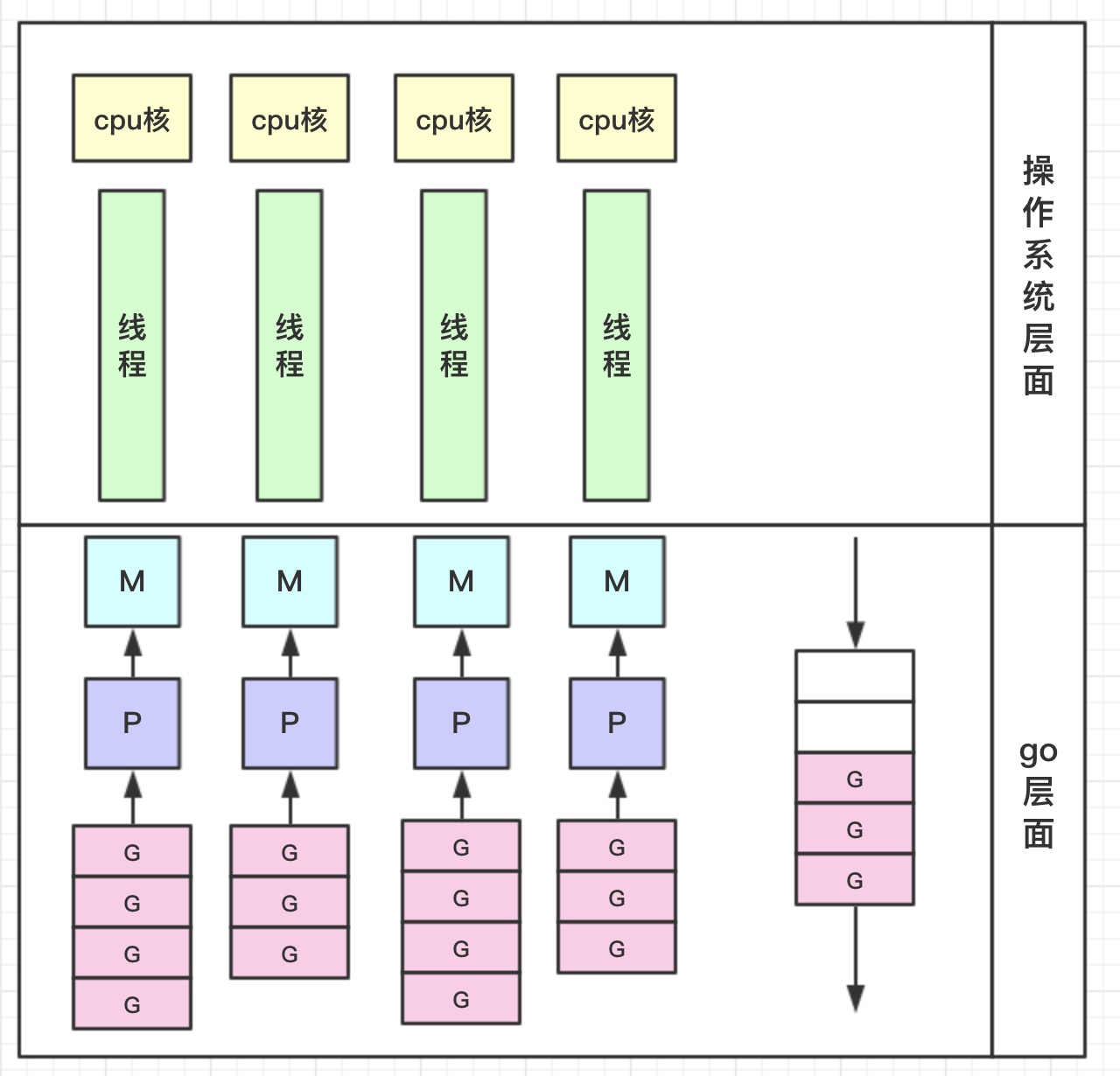
看到这个图你应该理解了一半,下面我来说明一下。
我们知道,在操作系统眼里其实只有cpu和线程,它去控制着各个线程的调度,切换,执行等等,而对于goroutine的实现其实非常类似;
在golang层面,首先我们要知道,最终在外面执行的肯定是线程,但是我们内部开出的那些goroutine到哪里去了呢?
golang提出GPM模型,在G的眼里,只有P,P保存了需要执行的那些goroutine;
而在整个go调度的层面,对外的是M,P会找到一个M,让它去与外面的线程交互,从而去真正执行程序。
从这里我们可以发现,其实goroutine的调度器整个就是一个小型的操作系统,内部去造出了类似的部件去完成goroutine的实现,而因为是在内部实现,所以解决了操作系统层面所带来的线程创建慢等问题。
但是,同时这样的调度也会有问题,所以需要一些额外的措施!
调度中的问题
问题1 G不均
我们知道,现实情况有的goroutine运行的快,有的慢,那么势必肯定会带来的问题就是,忙的忙死,闲的闲死,go肯定不允许摸鱼的P存在,势必要榨干所有劳动力。
如果你没有任务,那么,我们看到模型中还有一个全局G队列的存在,如本地队列已满,会一次性转移半数到全局队列。其他闲的小伙子就会从全局队列中拿;(顺便说一下,优先级是先拿下一个需要执行的,然后去本地队列中拿,再去全局队列中拿,先把自己的做完再做别人的嘛)同时如果全局都没有了,就会去抢别人的做。
问题2 任务卡主了
万一有个程序员启动一个goroutine去执行一个任务,然后这个任务一直睡觉(sleep)就是循环睡觉,那咋办嘛!你作为执行人,你总不能说,让它一直占用着一整个线程的资源,然后后面的goroutine都卡主了,那如果只有一个核心P,不就完蛋了?聪明的go才不会那么傻,它采用了抢占式调度来解决这个问题。只要你这个任务执行超过一定的时间(10ms),那么这个任务就会被标识为可抢占的,那么别的goroutine就可以抢先进来执行。只要下次这个goroutine进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入P的本地队列里面等待下次执行。
谁来做的呢?
sysmon,就是这个背后默默付出的人,它是一个后台运行的监控线程,它来监控那些长时间运行的G任务然后设置可以强占的标识符。(同时顺便提一下,它还会做的一些事情,例如,释放闲置的span内存,2分钟的默认gc等)
问题3 阻塞可怎么办?
我们经常使用goroutine还有一个场景就是网络请求和IO操作,这种阻塞的情况下,我们的G和M又会怎么做呢?
这个时候有个叫做netpoller的东西出现了,当每次有一个网络请求阻塞的时候,如果按照原来的方法这个时候这个请求会阻塞线程,而有了netpoller这个东西,可以将请求阻塞到goroutine。
意思是说,当阻塞出现的时候,当前goroutine会被阻塞,等待阻塞notify,而放出M去做别的g,而当阻塞恢复的时候,netpoller就会通知对应的m可以做原来的g了。
同时还要顺便提一句,当P发现没有任务的时候,除了会找本地和全局,也会去netpoll中找。
问题4 系统方法调用阻塞?
还有一个问题,我们自己想可能比较难想到,就是当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞就比较麻烦了。下面引用一段话:
当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于block on syscall状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
源码一瞥
1 | struct G |
总结
goroutine的设计总的来说就是参考操作系统的设计,所有的目的很明确就是为了在整个运行过程中能充分利用已有的资源,尽可能在有限的资源里面多做事情,利用gpm的模型以及一些netpoller、sysmon等帮助在阻塞的时候也能合理利用资源,从而达到我们现在高效的goroutine
参考资料:
https://tiancaiamao.gitbooks.io/go-internals/content/zh/05.1.html
http://morsmachine.dk/go-scheduler
http://morsmachine.dk/netpoller
https://studygolang.com/articles/10116
 微信
微信 支付宝
支付宝
